Project 7 Telecom Clusters Analysis
7.1 Análise Exploratória dos Dados
A clusterização pode ser usada para agrupar clientes com base em semelhanças. A segmentação de clientes pode ser usada para criar estratégia de marketing apropriada para o segmento. Nesta atividade iremos analisar a clusterização k-means utilizando o dataset de uma operadora de Telecom. O dataset é composto por 1500 clientes e iremos analisar as variáveis de tempo médio usado em chamadas de longa distância, local e internacional para fazer a clusterização.
Vamos iniciar explorando os dados:

## longdist internat local
## Min. : 0.00 Min. : 0.00 Min. : 8.19
## 1st Qu.:20.17 1st Qu.: 0.00 1st Qu.: 49.57
## Median :25.98 Median : 1.84 Median : 59.83
## Mean :27.40 Mean : 5.45 Mean : 65.61
## 3rd Qu.:35.66 3rd Qu.:10.16 3rd Qu.: 70.08
## Max. :62.47 Max. :29.02 Max. :134.76Dos dados, vemos que as 3 variáveis apresem outliers sendo que a variável local é a que mais tem outliers. Além disso, o valor mínimo de longdist e internat é 0, o que faz sentido já que estamos analisando o tempo médio e variação dos dados é grande. Vamos padronizar e olhar os histograma das variáveis
## Zlongdist.V1 Zinternat.V1 Zlocal.V1
## Min. :-1.7031825 Min. :-0.801535 Min. :-1.6854918
## 1st Qu.:-0.4495639 1st Qu.:-0.801535 1st Qu.:-0.4708472
## Median :-0.0884570 Median :-0.530931 Median :-0.1696811
## Mean : 0.0000000 Mean : 0.000000 Mean : 0.0000000
## 3rd Qu.: 0.5131805 3rd Qu.: 0.692667 3rd Qu.: 0.1311915
## Max. : 2.1794926 Max. : 3.466352 Max. : 2.0297709
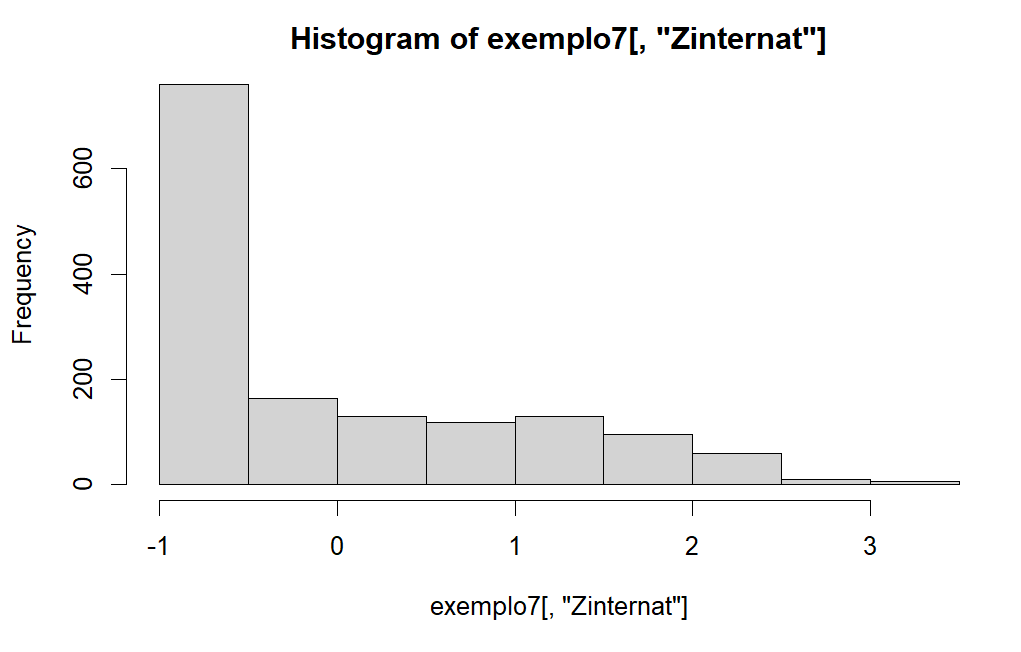
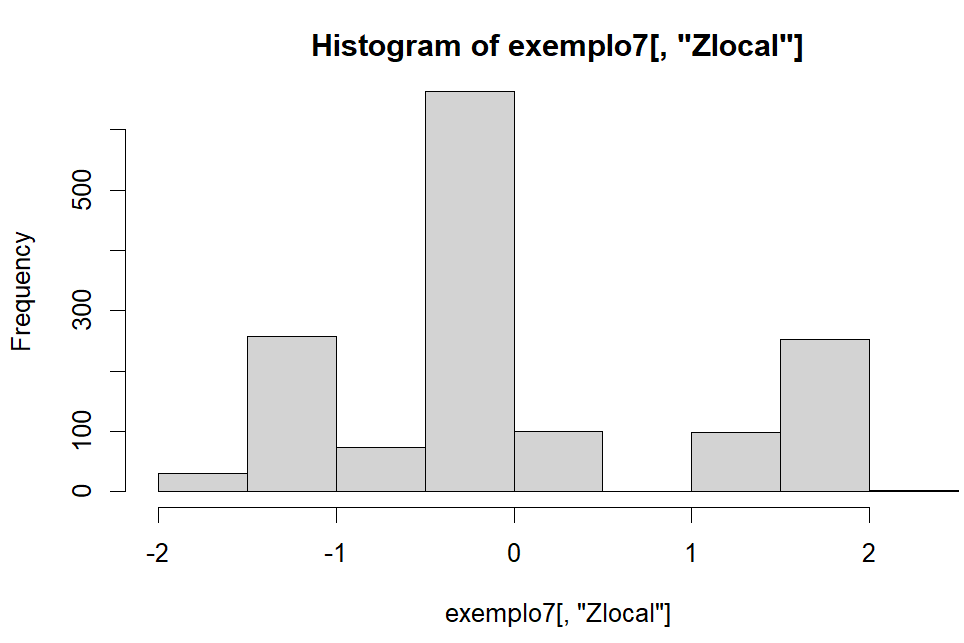
Do histograma podemos ver que a variável longist é que mais se aproxima de uma distribuição normal, já a variável internat temos uma distribuição skew à esquerda.
7.1.1 Estatística de Hopkins
Uma primeira análise que podemos começar é avaliar se existe estrutura nos dados para a formação de clusters, pois sabemos que sempre existirá formação de clusters nos dados. Para fazer essa análise podemos utilizar a estatística de Hopkins (H) que tenta analisar se de fato existe uma estrutura de clusters nos dados.
O que o algoritmo faz é gerar pontos aleatórios fora da amostra e selecionar pontos dentro da amostra e calcular a distância entre os pontos que foram pegos na amostra até o ponto mais próximo. Se o valor \(\mathbf{H}\) for maior que 0.75, então existe uma tendência de clusterizações nos dados com 90% de confiança.
# Análise Preliminar dos Dados
hopkins(exemplo7[1:3], m=nrow(exemplo7)*0.15)## [1] 0.9991904Do resultado nos nossos dados, obtemos um valor \(\mathbf{H} = 0.99\), o que mostra que o nosso dataset tem sim dados clusterizados.
7.1.2 Heatmap
Vamos ver o heatmap do dendrograma do dataset. Um dendrograma é um diagrama de árvores que agrupa as entidades que estão mais próximas umas das outras.
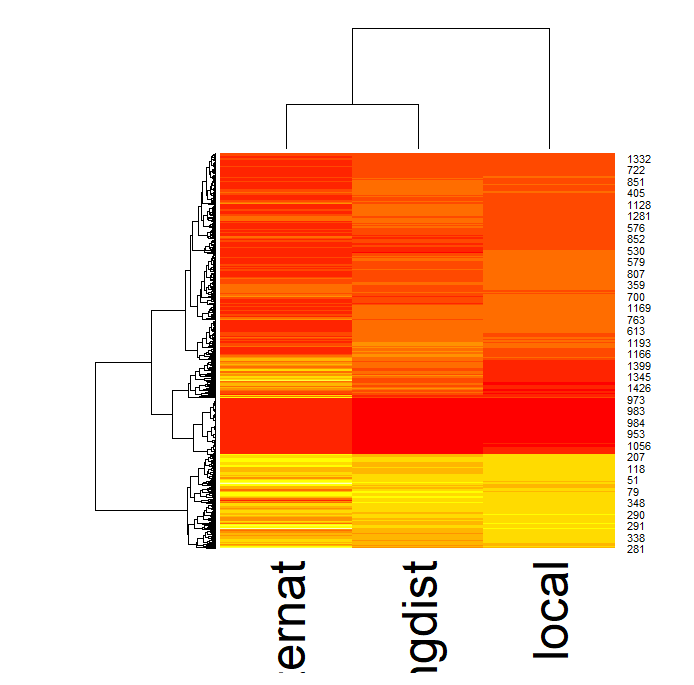
Conforme mostrado acima, o dendrograma reordena as observações com base na proximidade entre os dados usando alguma métrica de distância (neste caso a euclidiana). A árvore à esquerda do dendrograma representa a distância relativa entre nós. Podemos ver do dendrograma internat se juntando com longdist para depois se juntarem com local. No gráfico hierárquico na esquerda não está muito claro quantos grupos podemos ter, mas aparentemente desta análise inicial parece convergir para 3 grupos.
Vamos agora dar uma olhada na Matriz de Dissimilaridade
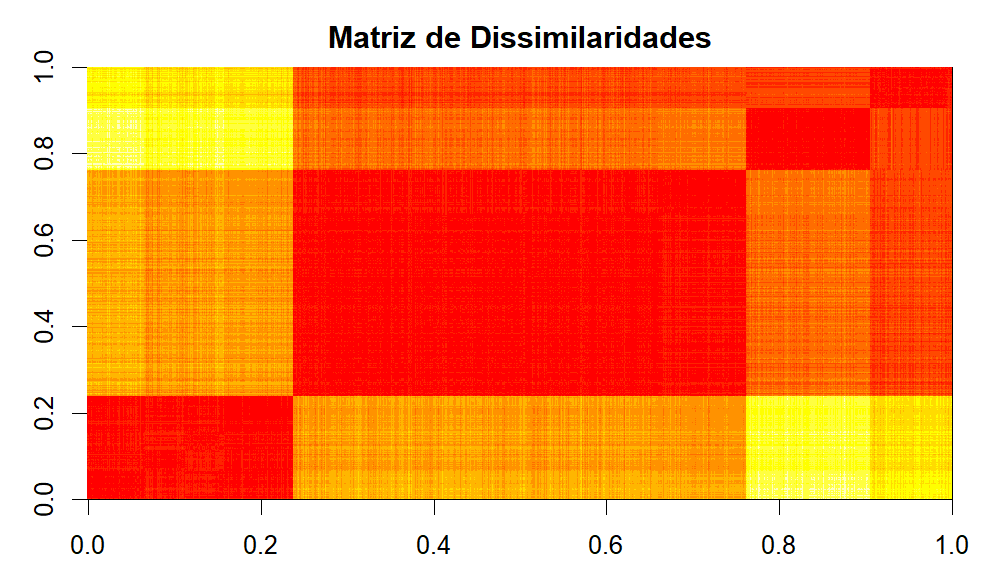
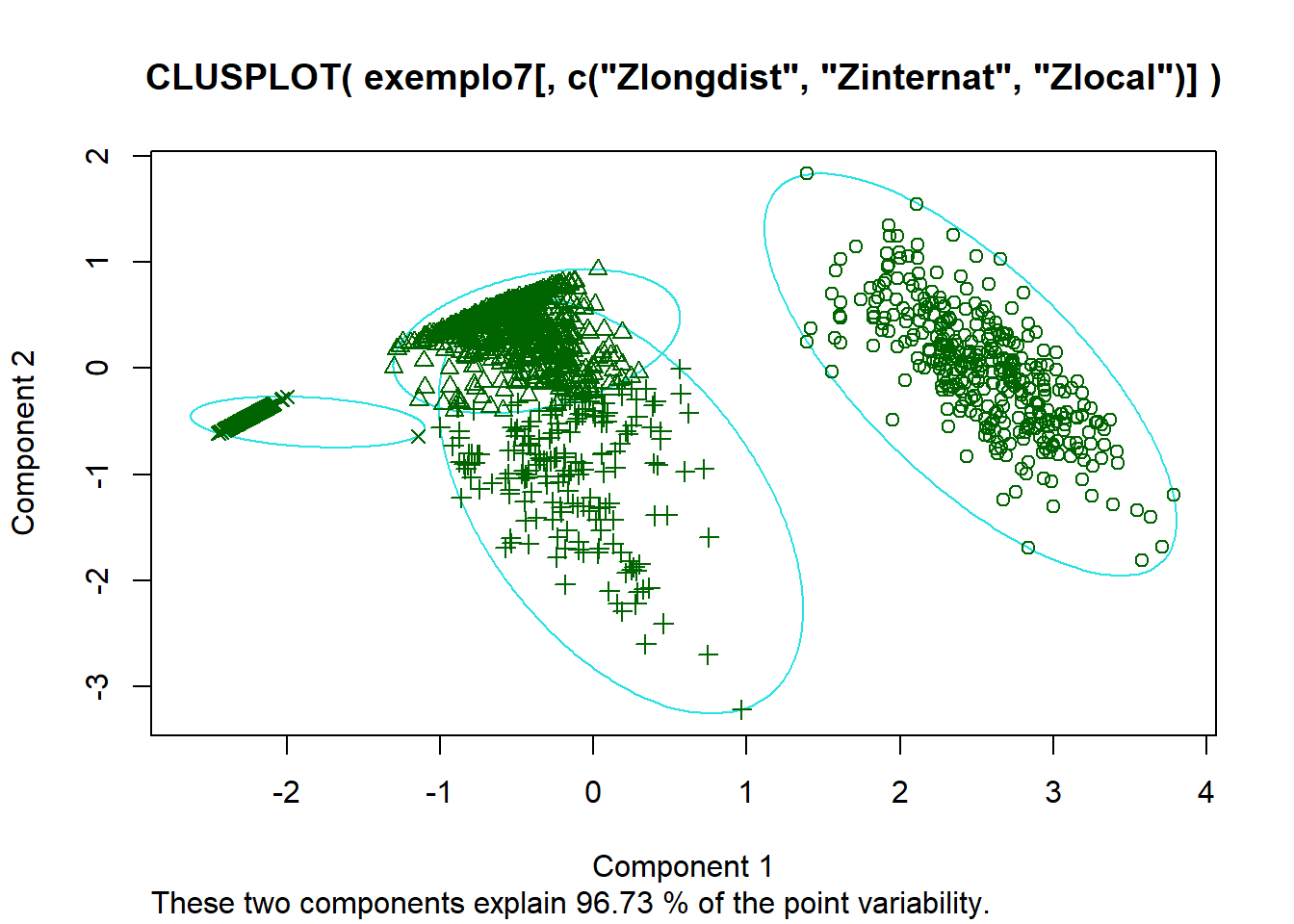
Da Matriz de Dissimilaridade é possível ver um grande grupo seguidos de um grupo médio e de 2 grupos menores.
7.1.3 Visualização 3d

Da visualização 3d podemos ver novamente 3 grupos assim como quando fizemos a análise do heatmap e um quarto grupo no eixo da variável local. Sabemos dos gráficos de boxplot que esses dados são possivelmente outlier, além disso, do gráfico de dissimilaridade vimos um pequeno grupo no quanto superior direito do gráfico que pode ser explicado por esses dados.
7.1.4 Análise de Multicolinearidade
Vamos ver agora como esta a multicolinearidade
## Zlongdist Zinternat Zlocal
## 5.941898 2.049105 5.222342Do resultado, podemos ver que as variáveis não são redundantes, tendo assim uma colinearidade baixa. Podemos então utilizar as 3 variáveis com segurança para fazer os clusters.
7.2 Análise de Clusters
Feito uma exploração inicial nos dados podemos agora de fato trabalhar na análise de Clusters.
Definição da Medida de Similaridade: Como as variáveis tem métricas em escalas diferentes, será utilizado a distância euclidiana com padronização.
Pressupostos:
- A amostra é considerada como representativa dos grupos de clientes da empresa
- Não existe problema de colinearidade
Para a análise de clusters será utilizado uma combinações entre os métodos hierárquicos e não-hierárquicos. O método hierárquico será utilizado para especificar os centroides e o não-hierárquico (k-means) será utilizado para realizar a clusterizaçao.
Vamos começar a análise dos clusters comparando 3 alternativas (Ward, Average, Centroids) pois são menos sensíveis a outliers.

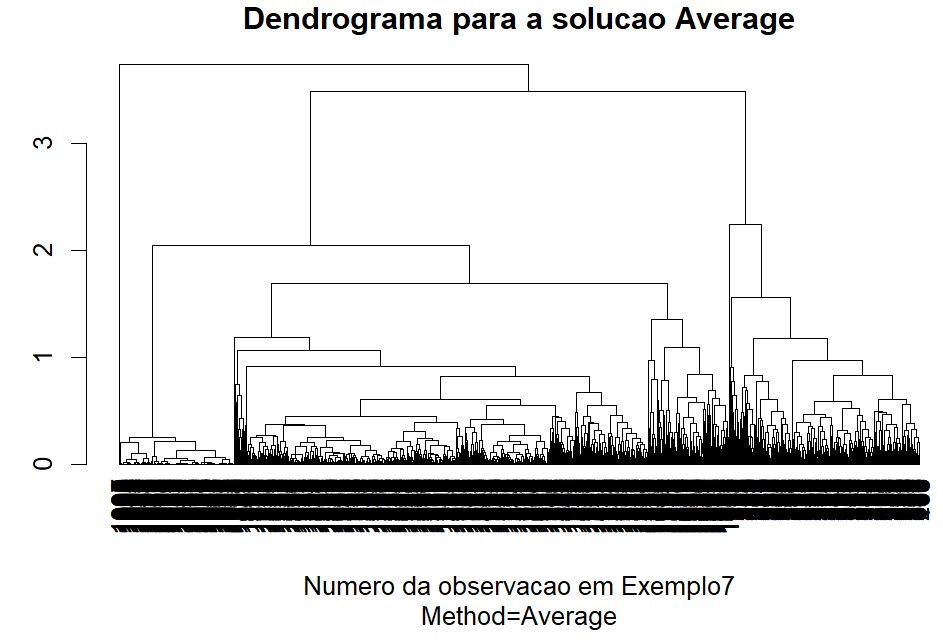
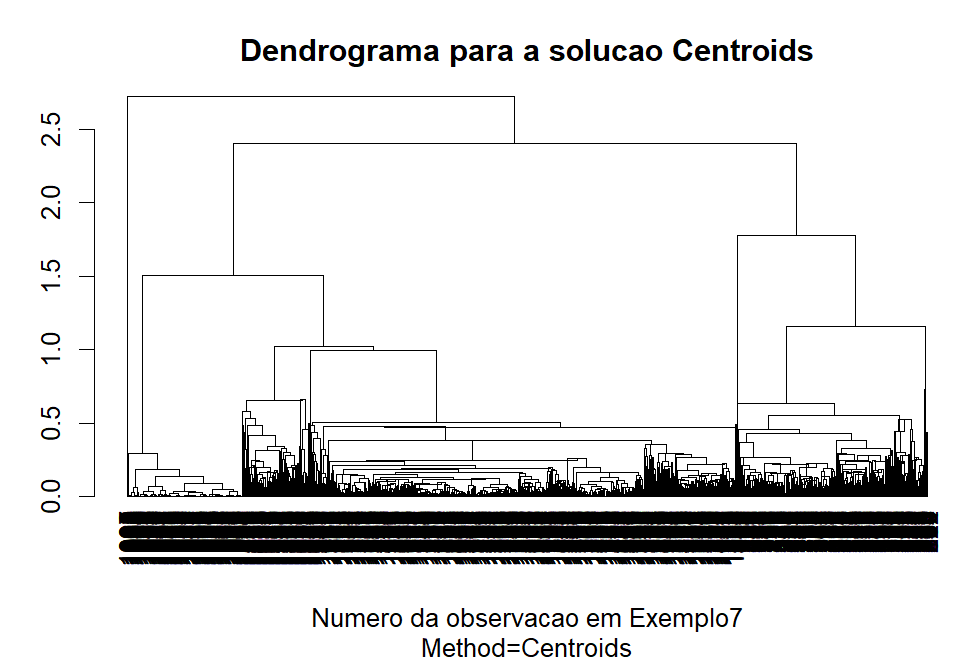
Dos dendrogramas gerados, o Ward aparenta ter o melhor comportamentos para os nossos dados apresentando clusters bem definidos. O método Average e Centroids acabaram gerando muita confusão na clusterização.
7.2.1 Definição da Quantidade de Clusters
Próxima etapa é olhar a quantidade ideal de clusters utilizando o método do cotovelo.

Do gráfico acima acima, vemos que o ideal número de clusters está entre 2 e 4, que é exatamente o número de clusters que as análises inicias indicavam. Vamos então analisar com essa quantidade de clusters.
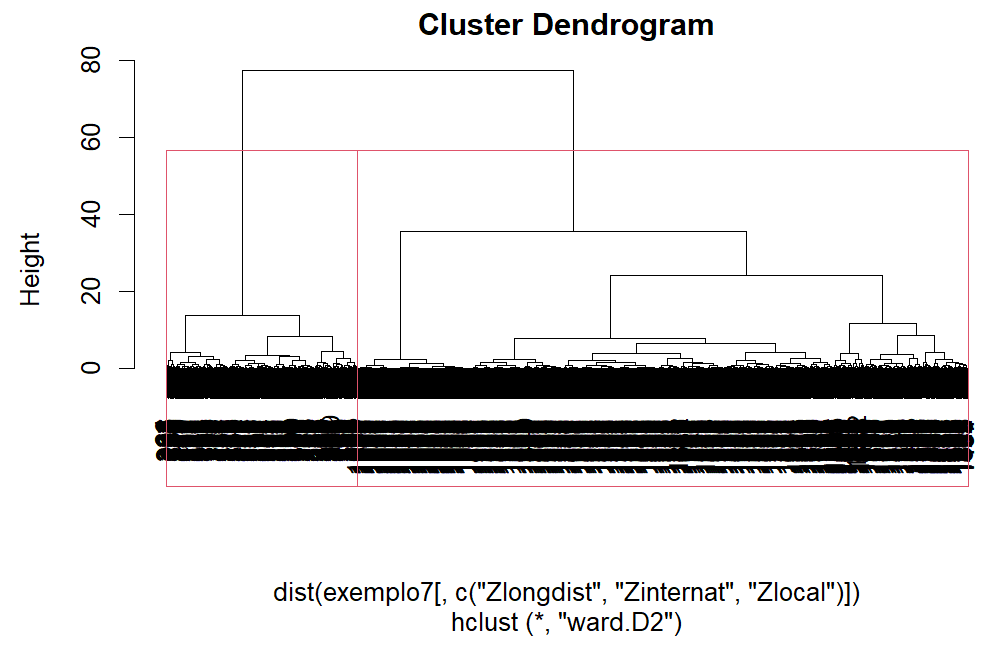
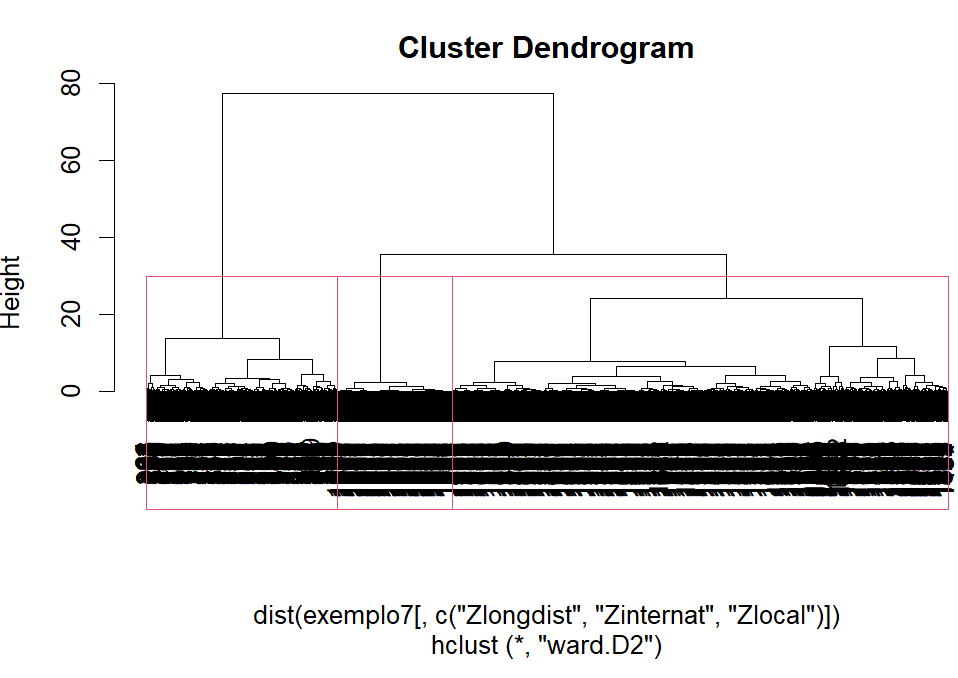

As 3 soluções parecem ser boas para utilizar na clusterizações de clientes. Por isso vamos fazer o perfil e interpretação para todas elas.
7.2.2 Perfil e Interpretação da Solução de 2 clusters
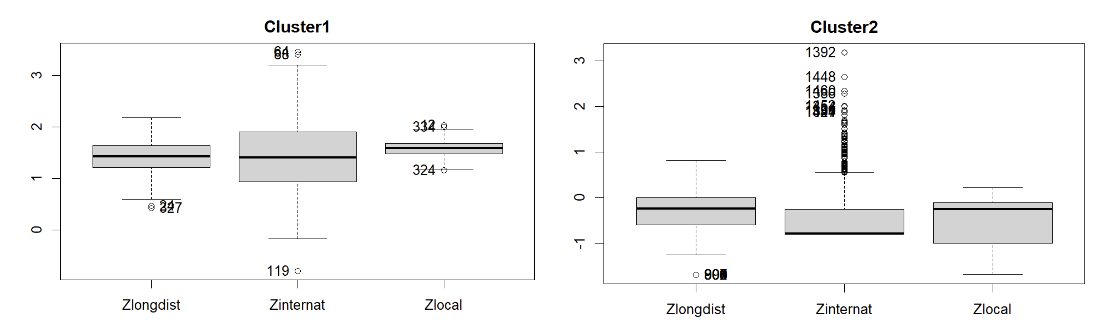
Analisando os grupos pelo bloxplot, vemos que no cluster1 a mediana das 3 variáveis são bem próximas e está entre 1 e 2. No cluster2 a mediana entre longdist e local continuam parecidas com mediana centrado em 0, já a internat fica menor.
## Df Sum Sq Mean Sq F value Pr(>F)
## hcw_2 1 938.8 938.8 2578 <2e-16 ***
## Residuals 1475 537.2 0.4
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Df Sum Sq Mean Sq F value Pr(>F)
## hcw_2 1 907.7 907.7 2356 <2e-16 ***
## Residuals 1475 568.3 0.4
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1## Df Sum Sq Mean Sq F value Pr(>F)
## hcw_2 1 1164.6 1164.6 5517 <2e-16 ***
## Residuals 1475 311.4 0.2
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Todos os grupos tem uma diferença estatística.

Quando dividimos em dois grupos vemos que são dois grupos distintos sem que exista mistura entre eles. No grupo da esquerda observamos uma agrupamentos de dados do lado esquerdo. Iremos ver mais adiante o que acontece quando aumentarmos o número de clusters.
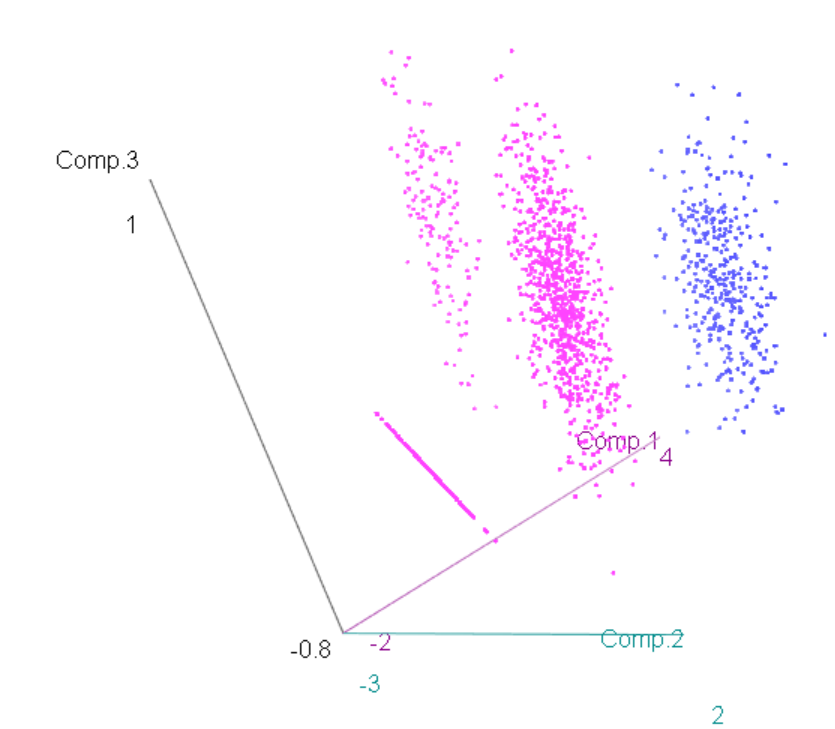
Da análise das componentes principais, utilizando 2 grupos podemos ver o grupo rosa parece ser segmentando em 3 grupos, indicando que talvez uma solução com 4 clusters seja mais indicado.
7.2.3 Perfil e Interpretação da Solução de 3 clusters
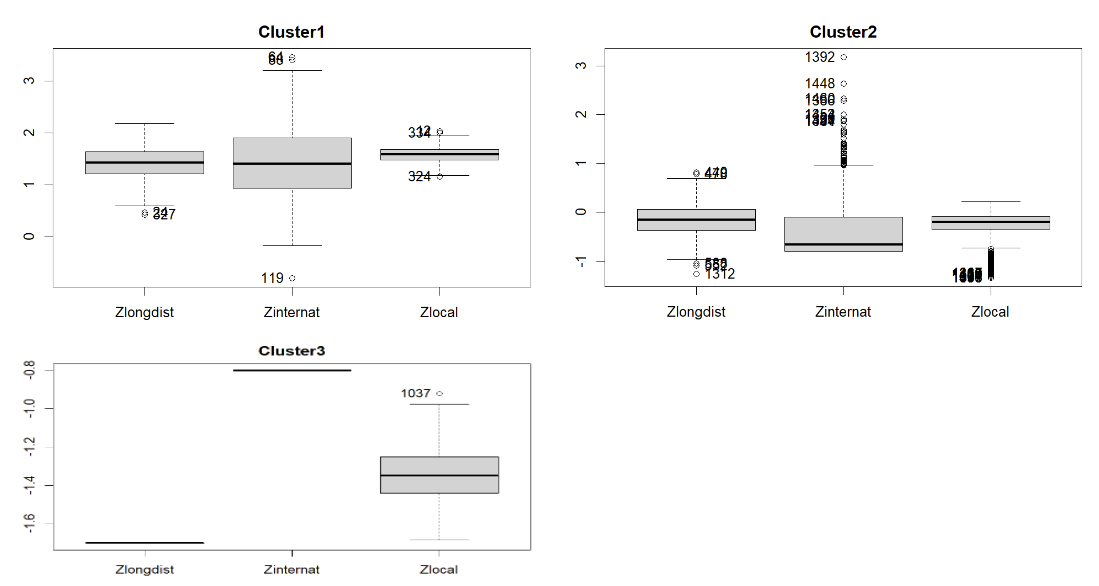
Analisando os grupos pelo bloxplot, vemos que no cluster1 a mediana das 3 variáveis são bem próximas e está entre 1 e 2. No cluster2 a mediana entre chamadas de longa distância e local continuam parecidas com mediana centrado em 0, já a chamada internacional fica menor igual vimos na análise com 2 clusters. Para o clusters 3, somente chamadas locais tem valores, o que era esperado pelo que comentamos no início e podemos existir grupo de pessoas que somente fazem chamadas locais.
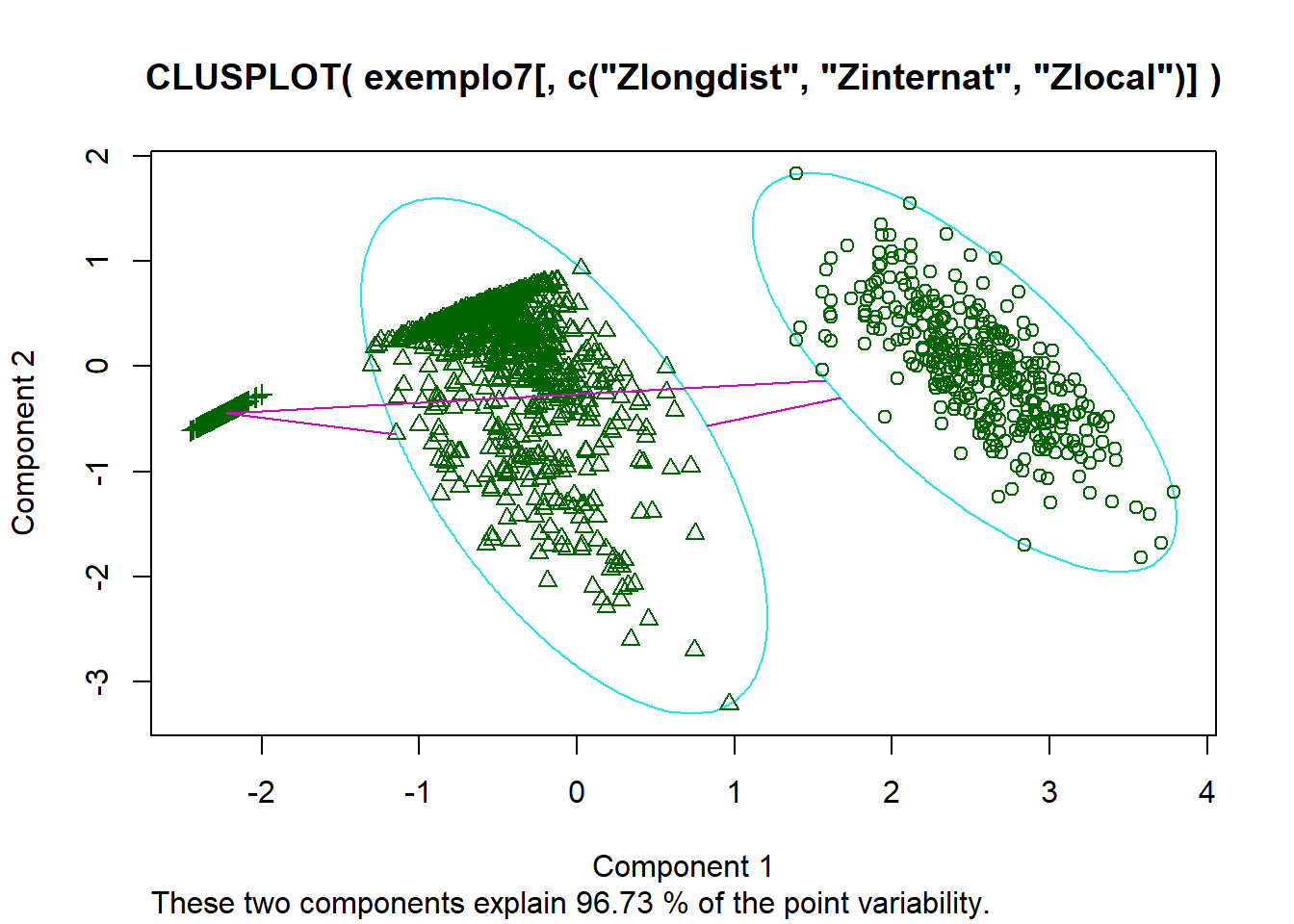

7.2.4 Perfil e Interpretação da Solução de 4 clusters

Na análise com 4 clusters vemos uma padrão bem parecido com o que ja vimos com 3 clusters no cluster 4 (lá era cluster 3) e cluster 1. Para o cluster 2 e cluster 3 temos uma mudança com a separação do grande grupo que tínhamos antes. Agora é possível ver que o grupo 2 prioriza mais chamadas locais e de longa distância, já o grupo 4 prefere chamadas internacionais.

No clusplot podemos ver que um grupo superpos outro quando aumentando para 4 clusters. Vamos dar uma olhada nas componentes principais.
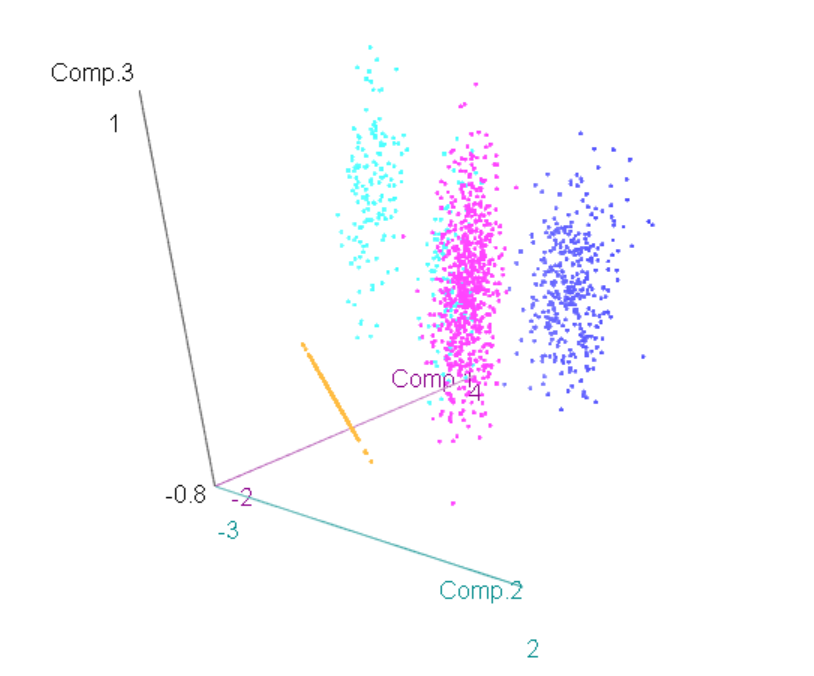
Da solução com 4 clusters, graficamente quando olhamos as componentes principais vemos uma mistura no maior grupo, acontecendo uma superposição entre o clusters azul claro e rosa. Vamos analisar se utilizando os clusters não-hierárquicos nós não conseguimos fazer uma separação melhor.
7.3 Clusters não-Hierárquicos
Agora que temos um análise mais clara dos clusters, iremos utilizar a solução para 3 ou 4 clusters para a clusterização não-hierárquica.
Vamos iniciar criando os centroides para as duas soluções
## hcw_3 V1 V2 V3
## 1 1 1.4252845 1.4015138 1.5874899
## 2 2 -0.1557206 -0.3547145 -0.3002139
## 3 3 -1.7031825 -0.8015346 -1.3478718## hcw_4 V1 V2 V3
## 1 1 1.4252845 1.4015138 1.5874899
## 2 2 -0.1696400 -0.6759335 -0.1690270
## 3 3 -0.1183404 0.5079141 -0.6525141
## 4 4 -1.7031825 -0.8015346 -1.3478718
Do resultados, obtivemos 2 clusters que têm centroids que fazem intersecçao entre os grupos o que não parece ser melhor que os grupos formados somente pela clusterização hierárquica.
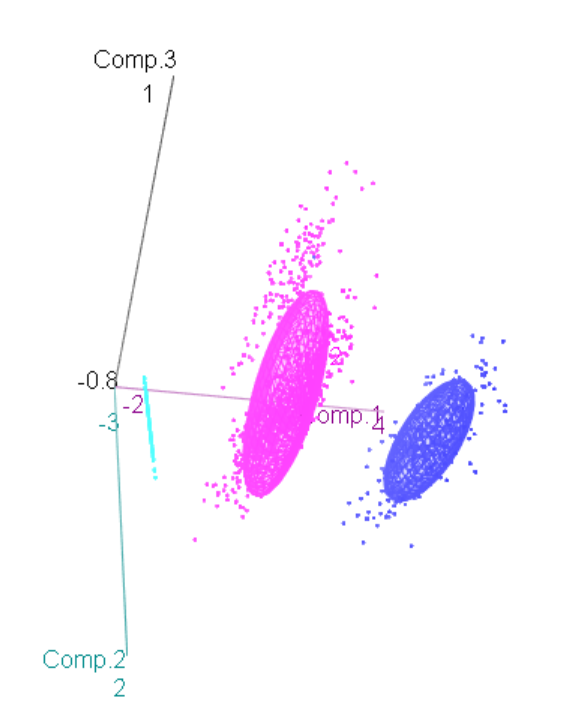
Vamos ver agora a formação para 4 clusters.
Para 4 clusters temos uma solução muito mais homogenia, com uma melhor separação entre os clusters meio.

Quando olhamos o gráfico em 3d com as componentes principais podemos ver uma separação muito melhor do que ocorreu com o caso de clusterização hierárquica.
7.4 Interpretação e Validação do Modelo
## INDICES: 1
## Zlongdist Zinternat Zlocal
## 1.420743 1.406559 1.579906
## ------------------------------------------------------------------------------------------------------
## INDICES: 2
## Zlongdist Zinternat Zlocal
## -0.1556963 -0.3585888 -0.2993492
## ------------------------------------------------------------------------------------------------------
## INDICES: 3
## Zlongdist Zinternat Zlocal
## -1.7031825 -0.8015346 -1.3478718## INDICES: 1
## Zlongdist Zinternat Zlocal
## 1.425285 1.401514 1.587490
## ------------------------------------------------------------------------------------------------------
## INDICES: 2
## Zlongdist Zinternat Zlocal
## -0.1608099 -0.6250803 -0.1811889
## ------------------------------------------------------------------------------------------------------
## INDICES: 3
## Zlongdist Zinternat Zlocal
## -0.1312782 0.7149430 -0.7684430
## ------------------------------------------------------------------------------------------------------
## INDICES: 4
## Zlongdist Zinternat Zlocal
## -1.6995970 -0.7981076 -1.34583127.4.1 Idade
Vamos analisar o perfil demográfico começando pela idade.
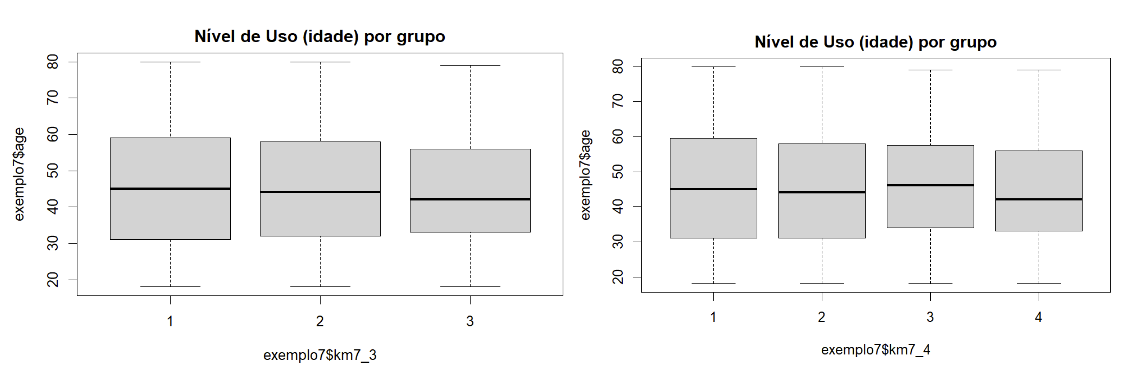
Com 3 grupos temos um perfil bem semelhantes entre os grupos. A mediana de todos eles estão entre 40 e 50 anos. Quando analisamos 4 grupos a mediana também apresenta uma idade entre 40 e 50 anos. Com uma mediana menor para o grupo 4 que só fazem ligações locais.
7.4.2 Sexo
Vamos agora olhar o perfil por sexo.
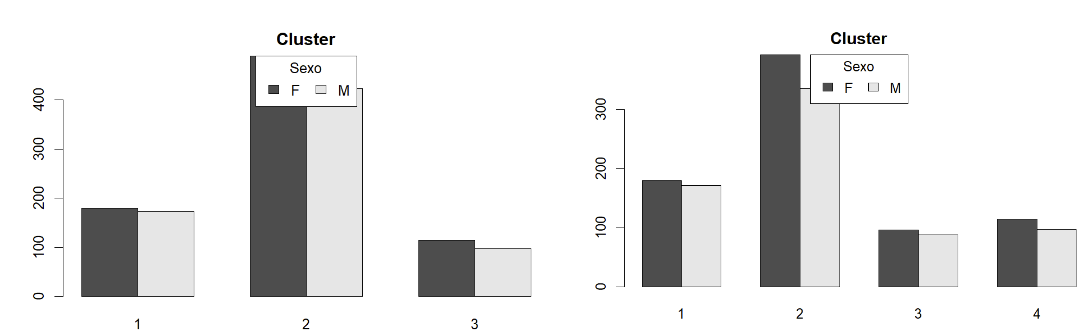
Para sexo tanto a solução para 3 quanto para 4 clusters apresentam um uso maior por mulheres.
7.4.3 Estado Civil
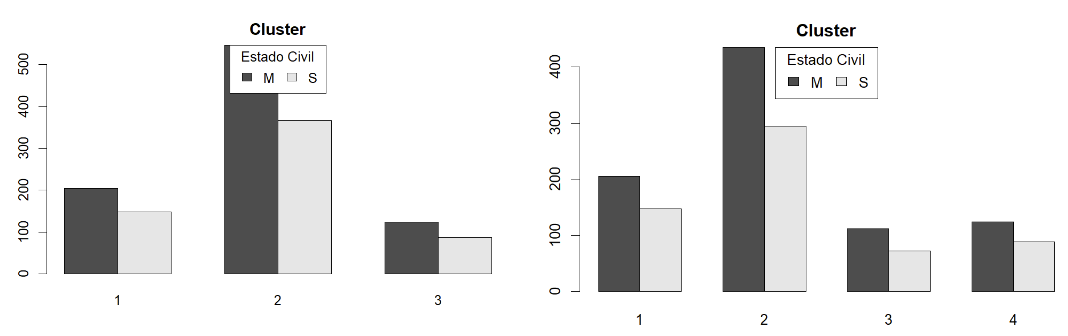
Para o caso do Estado Civil vemos que pessoas casadas são as que mais usam o serviços em todos os grupos em mandas as soluções.
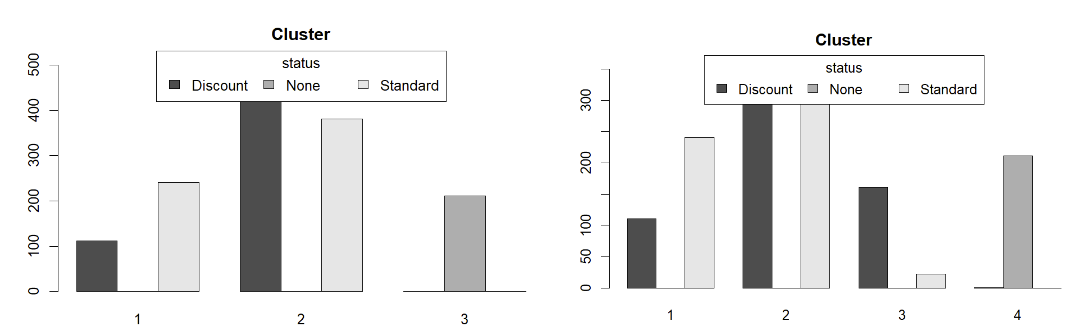

7.5 Conclusão
Da análise feita nos dados e nos métodos de Clusters hierárquico e não-hierárquico, chegamos na resposta que o número ideal de clusters para ser usado na empresa está entre 3 e 4. Além disso, dos métodos apresentados, utilizar o método Ward de clusterização hierárquica para descobrir os centroides e depois aplicar o método não-hierárquico k-means aparentou ser um método muito poderoso para clusterização.